Example Use Cases
Below are some examples to give a quick overview of what you can do with notebooks.Iterative Data Transformation
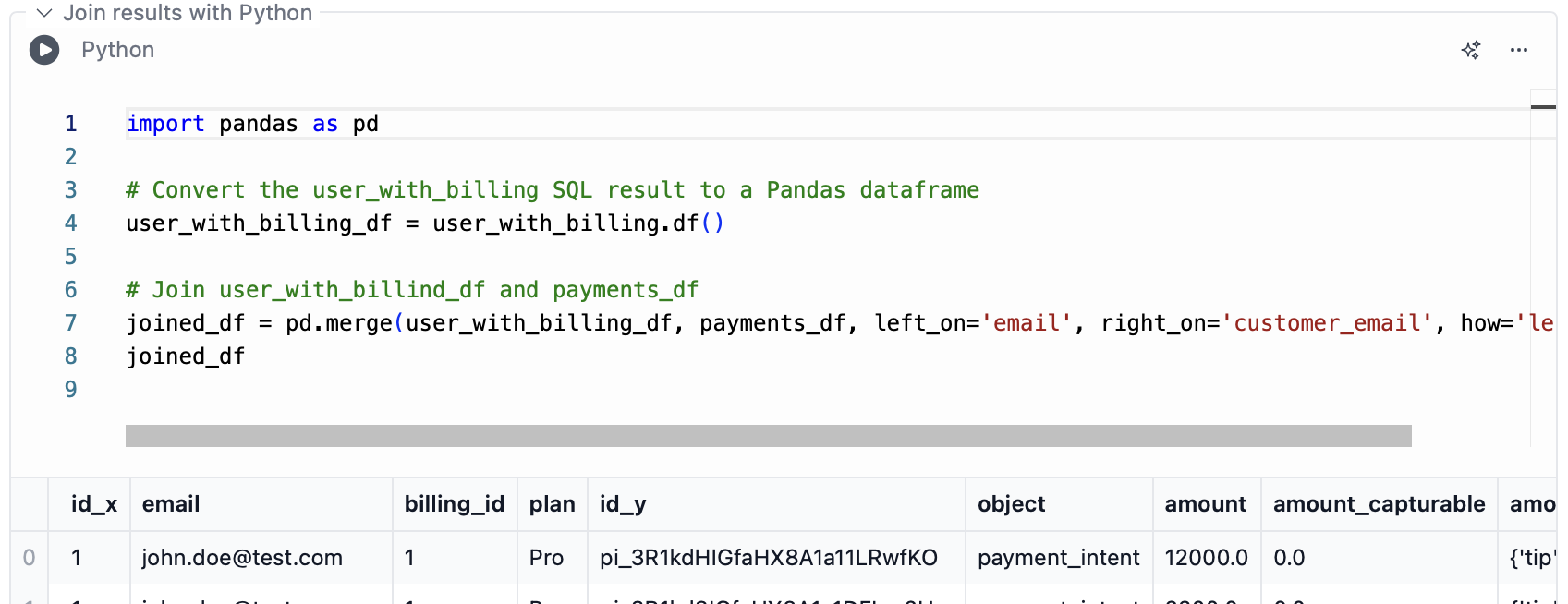
This example shows how to load and transform data iteratively, across multiple blocks, using both SQL and Python. What we’re doing here:- Load some data with SQL, store it in variable
user_with_billing - Load some more data with Python, store it in dataframe variable
payments_df - Join those two datasets using SQL. We’re using the built-in “Notebook session database” here, where all query results and Python dataframes can be queries as views.
user_with_billing) are also accessible in Python.
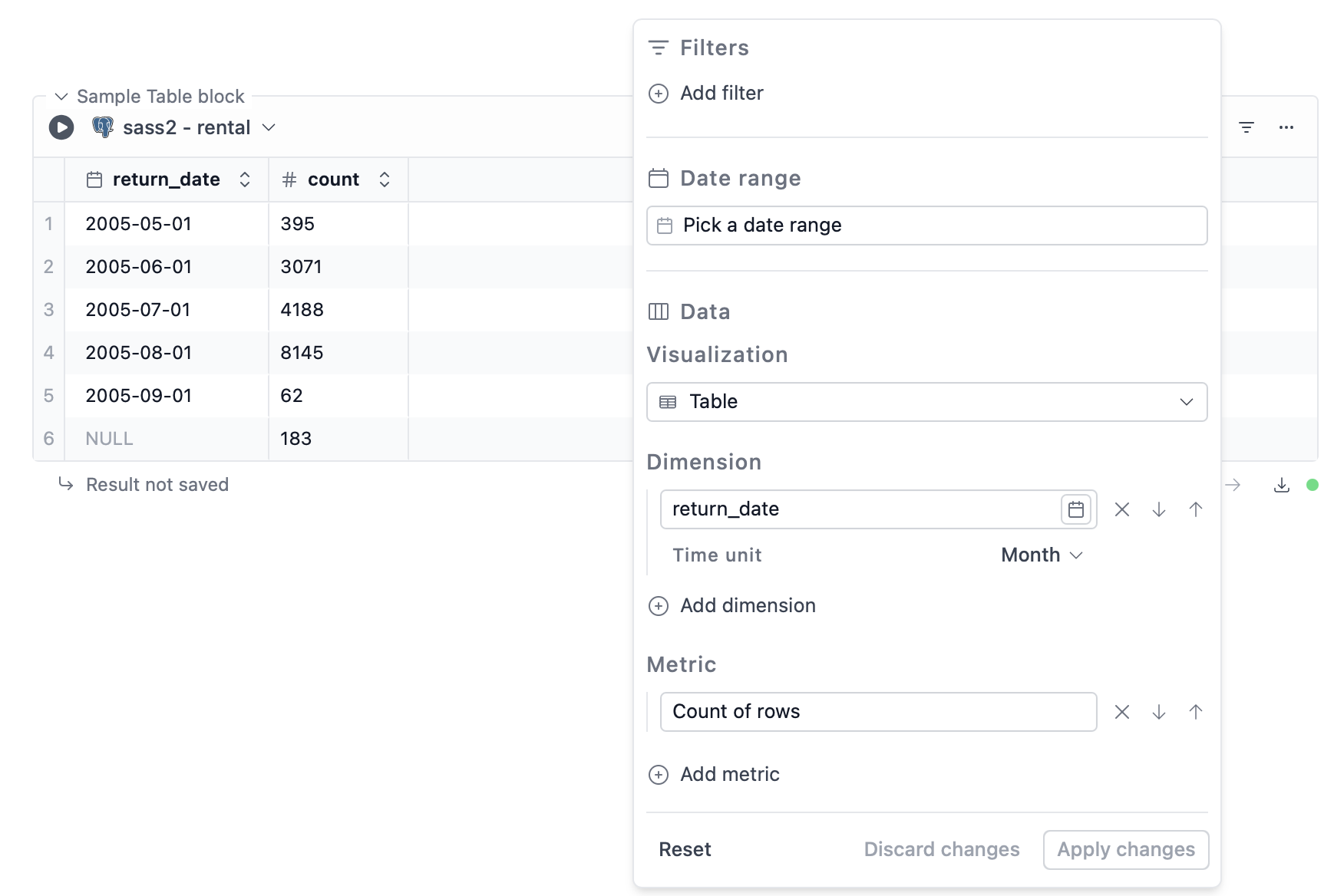
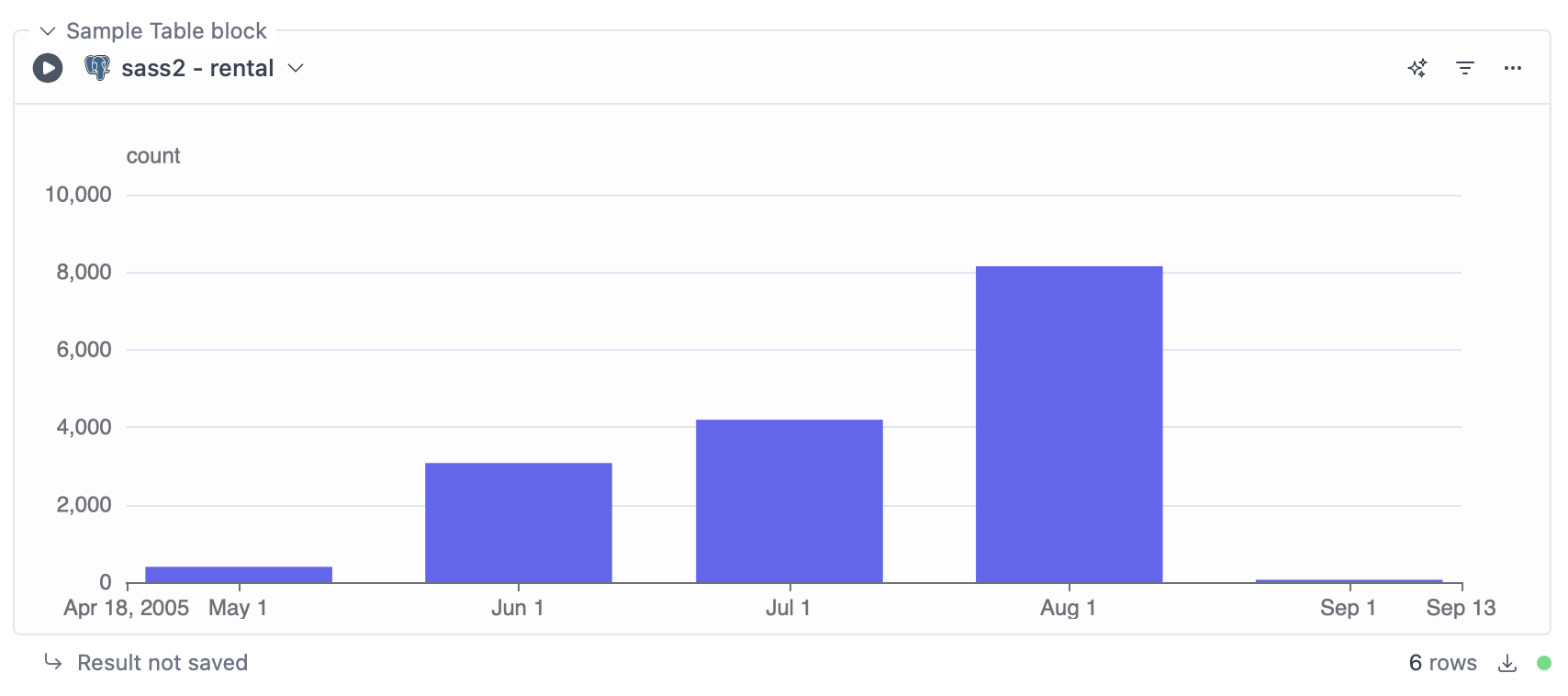
Dashboard for Time Series Data
This example shows how you can use a date range filter and chart blocks to visualize time series data, like orders and renewals over time.User Dashboard
This example shows a dashboard that allows entering a user email and then shows relevant data for that user. It also allows editing that data.Block Types
Notebooks support the following block types:SQL
Python
Table/Chart
Input
We currently support the following input block types:- Text
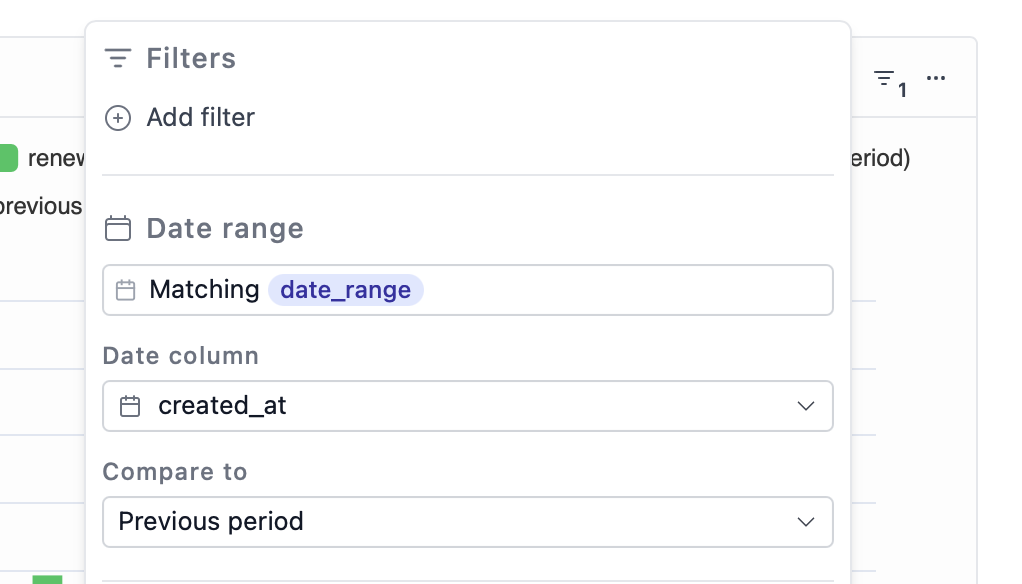
- Date range
- Toggle

How to use input block variables
Each input has a variable name. Using this name, the variable can be accessed in SQL, Python, and table/chart blocks. In Python: In Python, input variables are available as regular Python variables.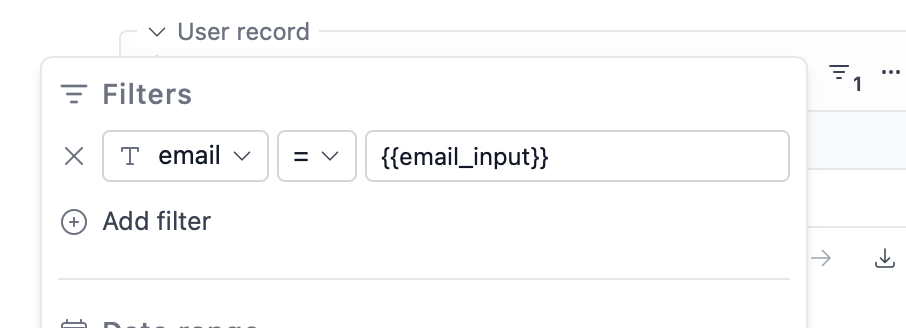
Text
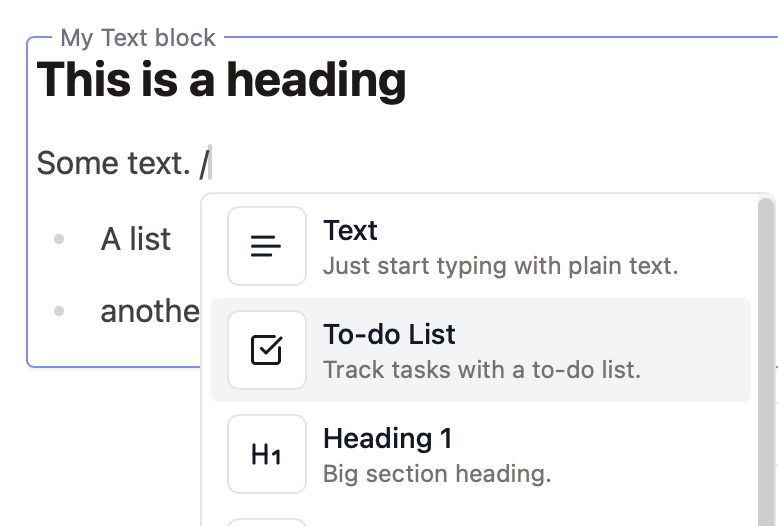
/ to open a menu with formatting options. You can also use Markdown syntax, e.g. type ## to create a H2 heading.
Query Results
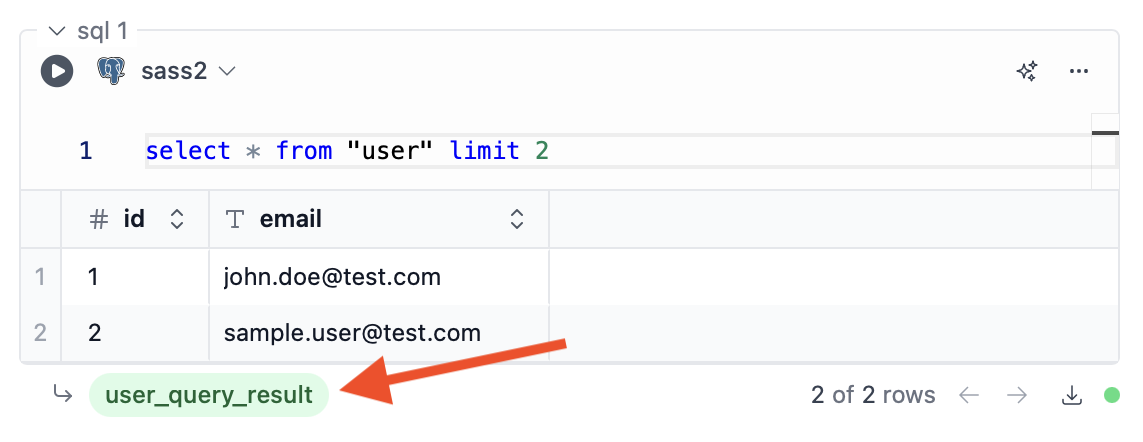
SQL blocks and table/chart blocks produce query results, which can be accessed in other blocks under the given variable name. SQL blocks always produce a stored result, as long as the query returns any data. For table/chart blocks, the result is only stored and accessible to other blocks if the table/chart block is configured to do so. The variable name of the block can be configured using the input at the bottom of the block. Here for example we’ve set it touser_query_result:
Access Query Results in Python
Query results in Python are thin wrappers around DuckDB’sDuckDBPyRelation class, so you can use any of its methods to fetch or further process the query result data.
Here are some examples:
Access Query Results in SQL
As a view in the Notebook session database
Query results are made available as a view in the “Notebook session database”, so you can query it like any other view or table in that database: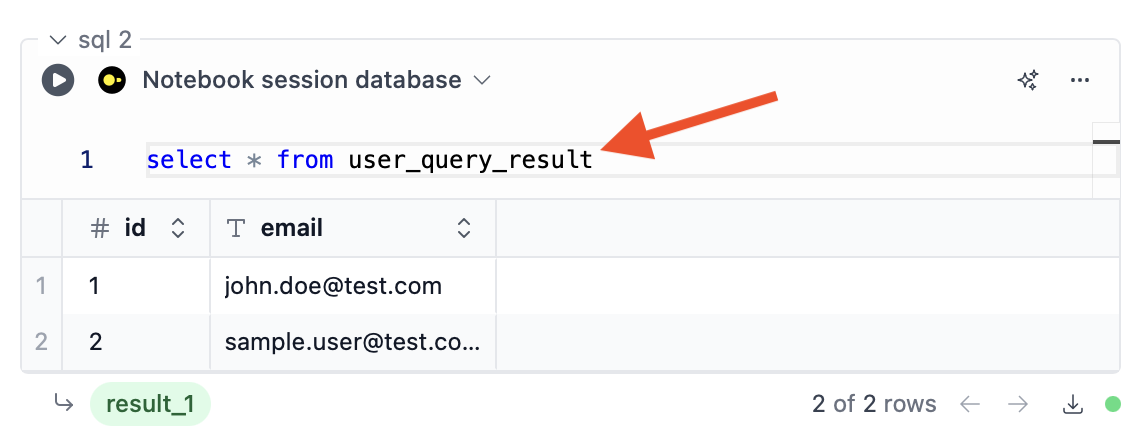
Using Jinja
You can also use the query result in a Jinja template. This can be used with any database connection, not just the notebook’s session database. In this example, we’re using the first column of the first row in the where clause: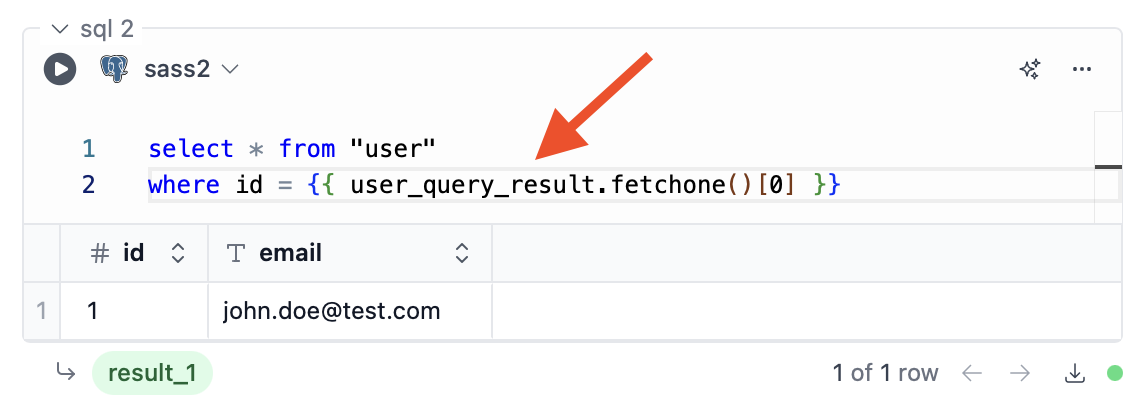
Access Query Results in Table/Chart Blocks
In table/chart blocks, you can use the query result as the data source, just like any regular table.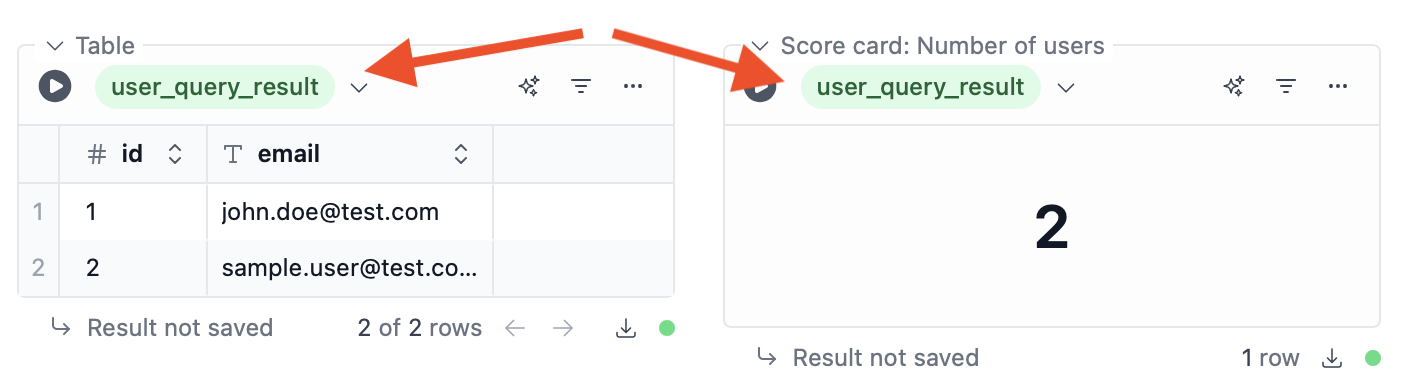
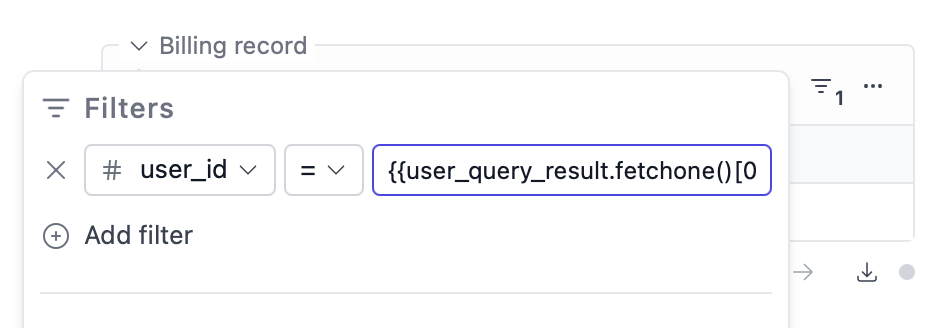
{{user_query_result.fetchone()[0]}})
Python
Supported Python versions
The following Python versions are supported:- 3.10
- 3.11
- 3.12
- 3.13
Managing Python Interpreters
You can select a Python interpreter per notebook at the top right of the notebook: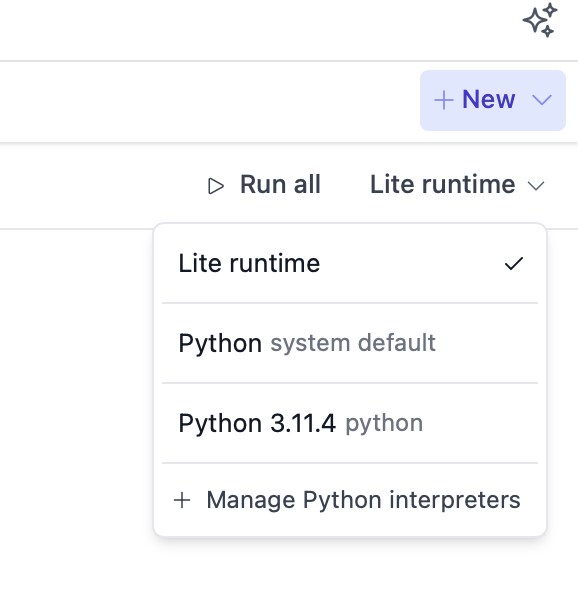
/Users/your-name/some-path/venv/bin/python.
Installing Dependencies
To install pip packages, use the%pip command in a Python block.
For example:
DataFrames
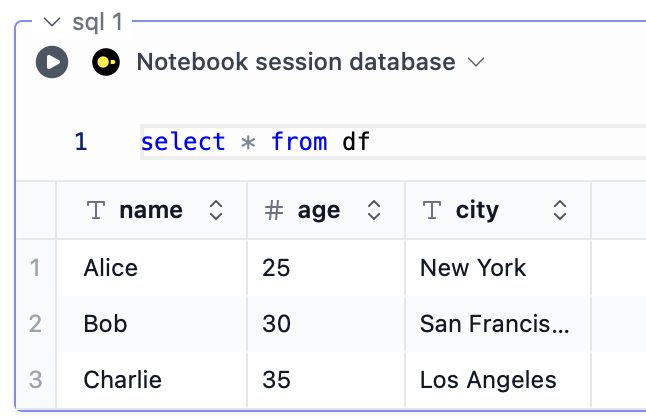
Python DataFrames, both Pandas and Polars, can be accessed in SQL blocks and table/chart blocks. Let’s say we have a Pandas DataFrame stored in the variabledf:
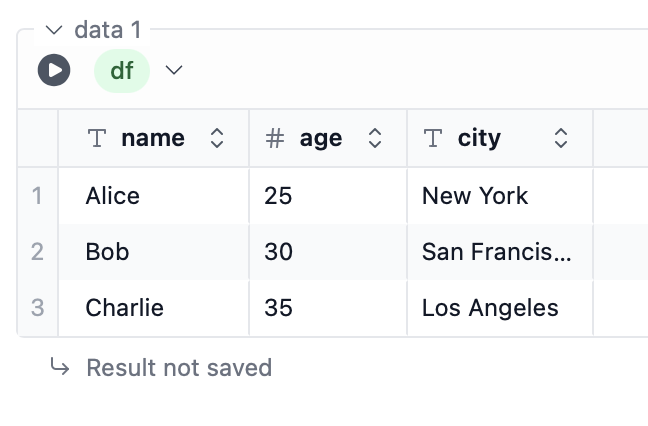
select * from df:
Polars
To use Polars, you’ll need to install thepolars and pyarrow packages manually. To do so, run the following command in a Python block:
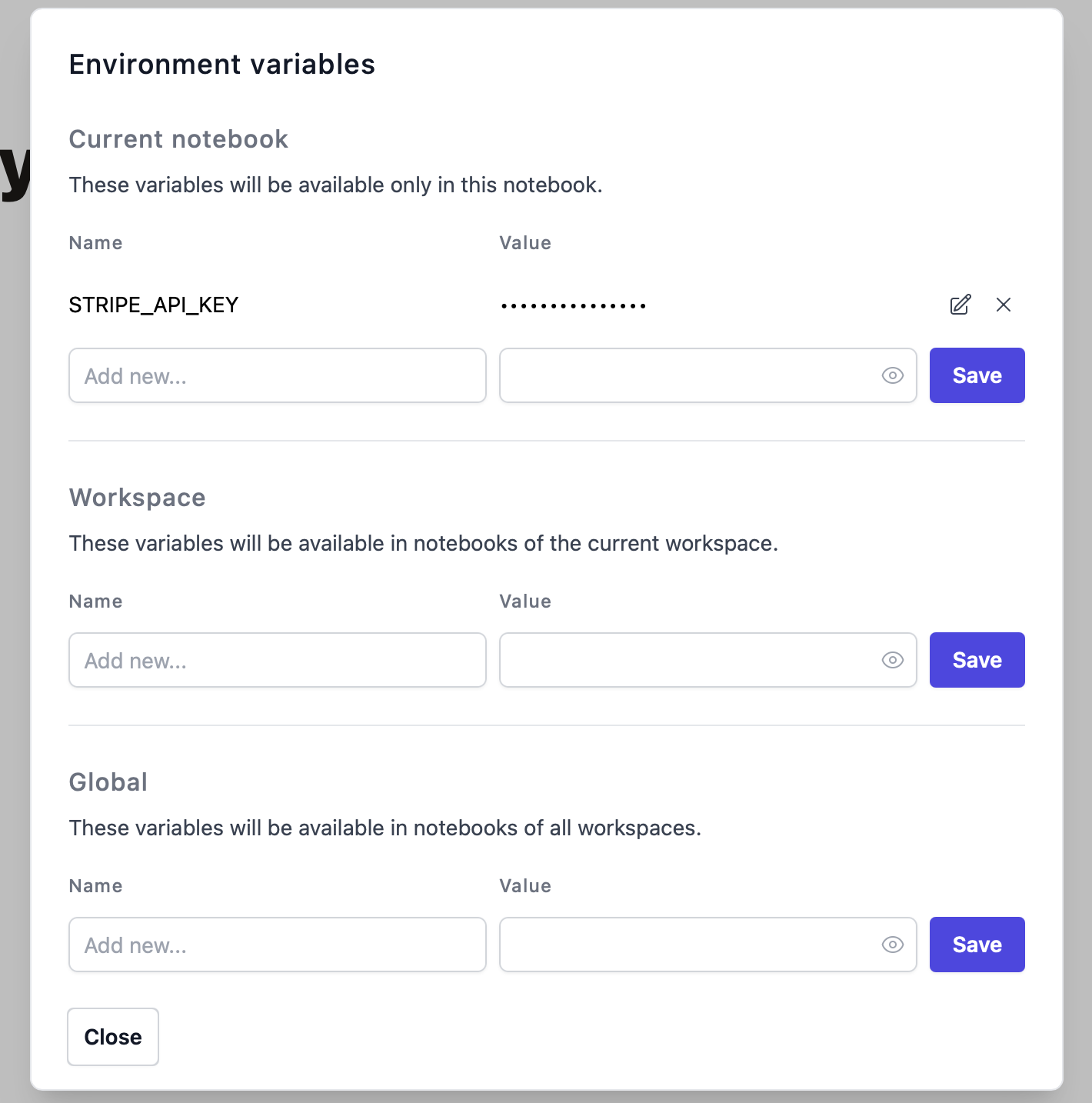
Environment Variables
You can configure environment variables, e.g. to store secrets. All variables are stored securely in your device’s keychain. To edit environment variables, click the menu button in the top left corner of the notebook: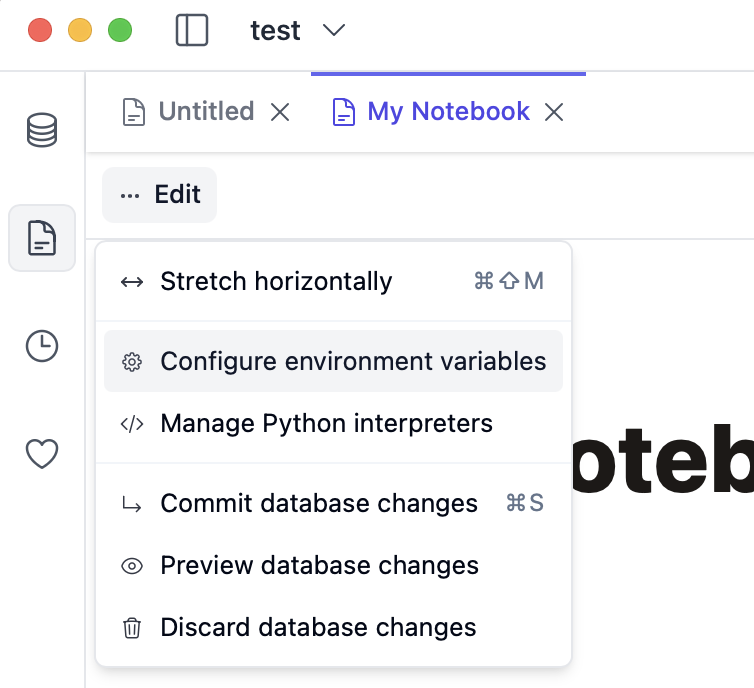
Using environment variables in Python blocks
Environment variables can be accessed usingos.environ. For example:
Using environment variables in SQL and table/chart blocks
Environment variables can be accessed using Jinja templating in SQL blocks and in filter values of table/chart blocks. For example in a SQL block:Jinja Filters for SQL Blocks
You can use Jinja in SQL blocks to parameterize your queries.Binding variables
By default, if you don’t specify any Jinja filter, the variable will be bound as a query parameter.bind filter if you prefer, which is equivalent to not specifying any filter:
Binding to IN clauses
You can bind Python lists to IN clauses using theinclause filter:
Binding to VALUES clauses
You can bind lists of lists to VALUES clauses using thevalues filter:
Parameterizing identifiers
To parameterize identifiers like table names, use theidentifier filter: